消息队列的应用场景
消息队列有很多的应用场景,比如流量削峰、数据分发、分布式事务等,之所以能支持这些应用场景,我个人认为是消息队列的两个核心特性在发挥作用:解耦和异步。
解耦
基于消息队列通信的情况下,生产者和消费者之间没有直接耦合。如果没有消息队列,每当一个新的业务方接入,我们都要联调新的接口。有了消息队列,生产者只需要关心消息是否成功发送到队列,至于如何消费消息是消费者自己的事情,这减少了开发和联调的工作量。 从面向对象编程的角度来说,消息队列相当于一个高度抽象的接口,通过实现这个接口,生产者和消费者都可以独立地修改现有的功能或加入新的扩展。
异步
在电子商务的一些秒杀促销活动中,使用消息队列可以提供流量削峰的作用。如果不使用消息队列,高并发的请求会让数据库压力剧增,使得响应速度变慢。如果将高并发产生的请求数据暂存在消息队列中,再由消费者进程从队列中获取数据并执行后续的业务逻辑,就可以有效抵御大量订单对系统的冲击。另外,假如系统需要进行故障修复或功能升级,数据也能暂存在消息队列中,等到系统恢复正常后,再从消息队列中获取数据并进行后续的处理。
消息队列带来的问题
系统可用性降低
系统引入的外部依赖越多,可用性就越低。
系统复杂度提高
消息没有被正确消费、消息重复消费、消息丢失、消息传递顺序错乱、 消息队列的高可用等这些以前没有的问题如今都需要解决。
消息模型
JMS 规范定义的消息模型有两种:点对点(Point To Point)和发布/订阅(Publish/Subscribe)。
点对点
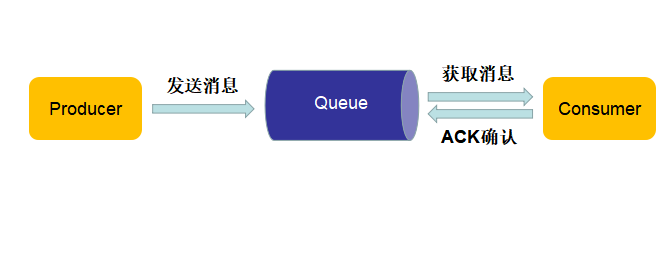
生产者将消息发送到队列中,消费者从队列中获取消息。
点对点模型的特点:
- 队列不能存储已经消费的消息,消费者不可能消息到已经被消费的消息
- 每个消息只有一个消费者和一个生产者
- 生产者发消息和消费者消费消息是异步解耦的
- 消费者接收到消息后,需要发送 ACK 确认。
发布/订阅
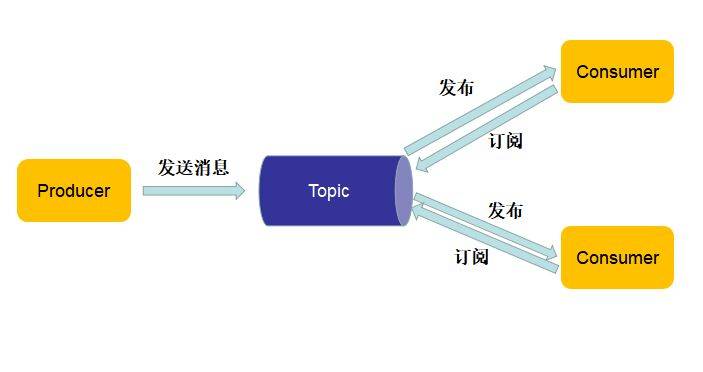
生产者将消息发布到话题中,所有订阅了话题的消费者都可以获取话题中的消息。
发布/订阅模型的特点:
- 每条消息都可以有多个消费者
- 消息者必须订阅 Topic 才可以消费生产者发布到 Topic 中的消息
- Topic 中的消息可被重复消费
推拉模型
消费者获取消息的方式分为两种,Push 和 Pull,也就是推送和拉取。Push 模型是指一旦有新的消息产生,消息队列就推送消息给消费者,而 Pull 模型是由消费者定时去队列拉取消息。两种模型在不同的应用场景中各有优势:
实时性要求高的场景
采用 Push 模型的情况下,一旦消息到达,服务端即可马上将其推送给消费者,这种方式的实时性非常好;而采用 Pull 模型的情况下,为了不给服务端造成压力,消费者需要控制好轮询的间隔时间,而且当数据量不足时,不停的轮询显得毫无意义,这必然会给实时性带来一定的影响。
生产速率大于消费速率的场景
当生产速率大于消费速率时,有两种可能性:一种是生产者本身的效率就要比消费者高,例如消费者处理消息的业务逻辑可能很复杂,或者涉及到磁盘、网络等 I/O 操作;另一种是消费者出现故障,导致短时间内无法消费或消费不畅。Push 模型由于无法得知当前消费者的状态,只要有数据产生,便会不断地进行推送。在以上两种情况下,可能会导致消费者的负载进一步加重,甚至崩溃,除非消费者有合适的反馈机制能够让服务端知道自己的状况。而采取 Pull 模型问题就简单了许多,由于消费者是主动到服务端拉取数据,此时只需要降低访问频率即可。
消息队列产品比较
| 维度 | Kafka | RabbitMQ | ZeroMQ | RocketMQ | ActiveMQ |
|---|---|---|---|---|---|
| 资料数量 | 资料数量中等,有文档也有书籍 | 资料数量多,有文档也有书籍 | 资料数量少 | 资料数量少,官方文档较简洁,有书籍 | 资料数量多,有文档也有书籍 |
| 开发语言 | Scala | Erlang | C | Java | Java |
| 协议 | 基于 TCP 的自定义协议 | AMQP | TCP、UDP | 基于 TCP 的自定义协议 | OpenWire、STOMP、REST、XMPP、AMQP |
| 消息存储 | 内存、磁盘、数据库,支持大量堆积 | 内存、磁盘,支持少量堆积 | 消息发送端的内存或者磁盘中,不支持持久化 | 磁盘,支持大量堆积 | 内存、磁盘、数据库,支持少量堆积 |
| 消息事务 | 支持 | 支持 | 不支持 | 支持 | 支持 |
| 负载均衡 | 支持 | 对负载均衡的支持较差 | 去中心化,不支持负载均衡,本身只是一个多线程网络库 | 支持 | 支持,可以基于zookeeper实现负载均衡 |
| 集群方式 | 无状态集群,每台服务器既是 Master 也是 Slave | 支持简单集群模式,比如主备,对高级集群模式支持不好 | 去中心化,不支持集群 | 常用多对 Master-Slave 模式 | 支持简单集群模式,比如主备,对高级集群模式支持不好 |
| 管理界面 | 一般 | 良好 | 无 | 一般 | 一般 |
| 可用性 | 非常高(分布式) | 高(主从) | 高 | 非常高(分布式) | 高(主从) |
| 消息重复 | 支持at least once、at most once | 支持at least once、at most once | 差 | 支持at least once | 支持at least once |
| 吞吐量 | 极大 | 大 | 极大 | 很大 | 不大 |
| 订阅形式和消息分发 | 基于topic以及按照topic进行正则匹配的发布订阅模式 | direct、topic、headers、fanout | 点对点 | 基于topic/messageTag以及按照消息类型、属性进行正则匹配的发布订阅模式。 | 点对点、发布-订阅 |
| 顺序消息 | 支持 | 不支持 | 不支持 | 支持 | 不支持 |
| 消息确认 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 消息回溯 | 支持指定分区offset位置的回溯 | 不支持 | 不支持 | 支持指定时间点的回溯 | 不支持 |
| 消息重试 | 不支持,但是可以实现 | 不支持,但是可以利用消息确认机制实现 | 不支持 | 支持 | 不支持 |
| 并发度 | 并发度高 | 并发度极高 | 并发度高 | 并发度高 | 并发度高 |